Allan Lin's Work Portfolio
CentML
May 2023 - Dec 2023
I interned at CentML working on their open source compiler machine learning compiler, Hidet. Here is a record of my contributions to the project: All PRs.
Some highlights of my time there are:
-
Wrote highly optimized convolution CUDA kernels
-
Designed a custom human-readable IR representation for the compiler backend. Previously the optimization IR had no roundtrippable text format, so I wrote the parser and printer.
- An IR representation is roundtrippable when
ir == parse(print(ir)) - PR
- An IR representation is roundtrippable when
-
Accelerated llama 2 by 1.5x from half precision, by developing int8 quantization compiler passes and kernels
-
Led the kernel development for AMD GPUs, matching the performance of AMD’s optimized matrix multiplication
- The process went something like this: we were a small team and to make our compiler compatible with AMD GPUs we needed performant matrix multiplication kernels that hooked into our compiler's optimization infrastructure. I was responsible for this part.
- I did various experiments in C++ trying to understand AMD's tensor-core instructions, a Public Repo contains my work on the matter, as well as some kernels in C++
- sadly, the final PR that implements the kernels in the Compiler's IR is private :(, here's a copy of the results: gist
-
My work resulted in co-authorship of a paper accepted to ASPLOS 26 – a prestigious conference for programming languages and computer systems
UofT EcoSys Lab
Jan 2024 - Mar 2024
I worked with them a bit part-time before I realized that I can't multitask very well. I implemented VLLM inference kernels in CUDA for them, for LLM stuff. PR
UWaterloo Applied and Principled PL Group
May 2024 - Aug 2024
I wrote a prototype compiler for the Familia programming language, using LLVM with Rust. What's cool with Familia is that it solves the expression problem, the feature is that classes can be arbitrarily nested within other classes kind of like modules, and the inheritance relations between classes is preserved. Another feature is that classes do not hold data like traditional OOP but are witnesses to interfaces, so kind of like one more layer of indirection where the class is a name that references an implementation of an interface for a data-type.
I significantly over-estimated my abilities and 4 months is no where enough time to finish a compiler for such a complex language. Some lessons were that Rust is not a good language for compilers, since the abstract syntax tree and internal representations have cyclic references that Rust's ownership system cannot model well. I've settled on an ID system that I've observed other compilers in Rust using, sort of like an entity-component-system design in game engines where IDs are integers that index into a global data-store. This incurred a lot of boiler-plate and productivity overhead though.
Waabi
Jan 2025 - Aug 2025
This is a recap of what I did (can't show PRs cuz NDA):
- Improved object detection metrics (IOU) by 5.7% in the perception model of Waabi’s autonomous vehicle
- Researched, trained and evaluated new object detection architectures
Essentially Waabi uses the Detra model in their autonomous system, with some proprietary enhancements of course. I evaluated several alternative architectures for the camera backbone and feature fusion mechanism that combines the LiDAR features with the camera features. Some problems with their old architecture is that it's not very scalable in terms of receptive field; the 3D features around the vehicle is projected into a dense birds-eye-view (BEV) feature map that does not scale well with respects to receptive field increases, as each xy region of space is represented by a pixel. I had some ideas with multi-scale feature maps, dynamic voxelization, and integrating a new LiDAR backbone Point Transformer V3.
- Reduced onboard inference time by 25ms by developing in-house sparse-convolution library
One of the team's sources of pain was the sparse-convolution library Torchsparse, which took a lot of developer time migrating across CUDA versions and inference time. I made a small but performant sparse convolution library that is both faster for the GPUs that we were using and much more maintainable, by leveraging Triton.
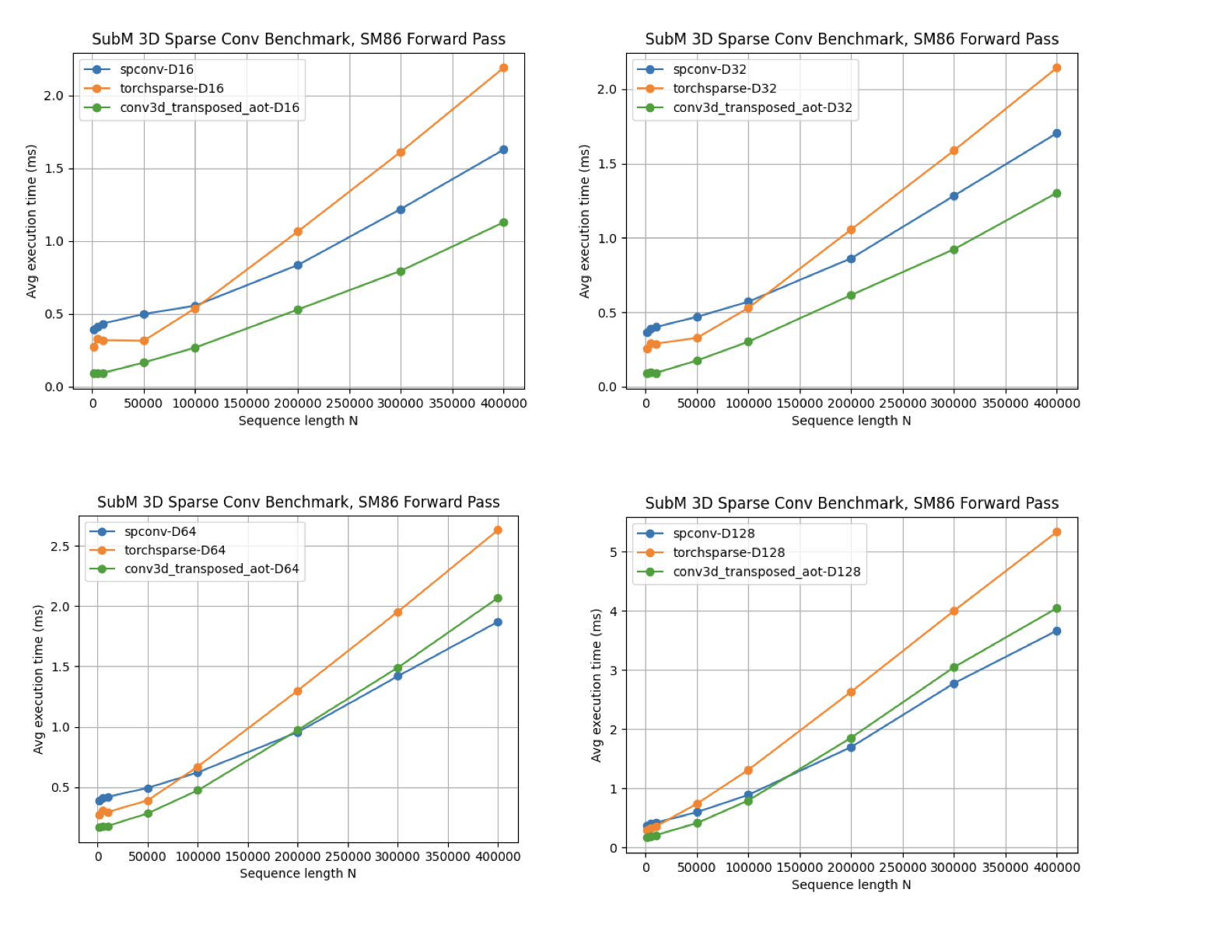
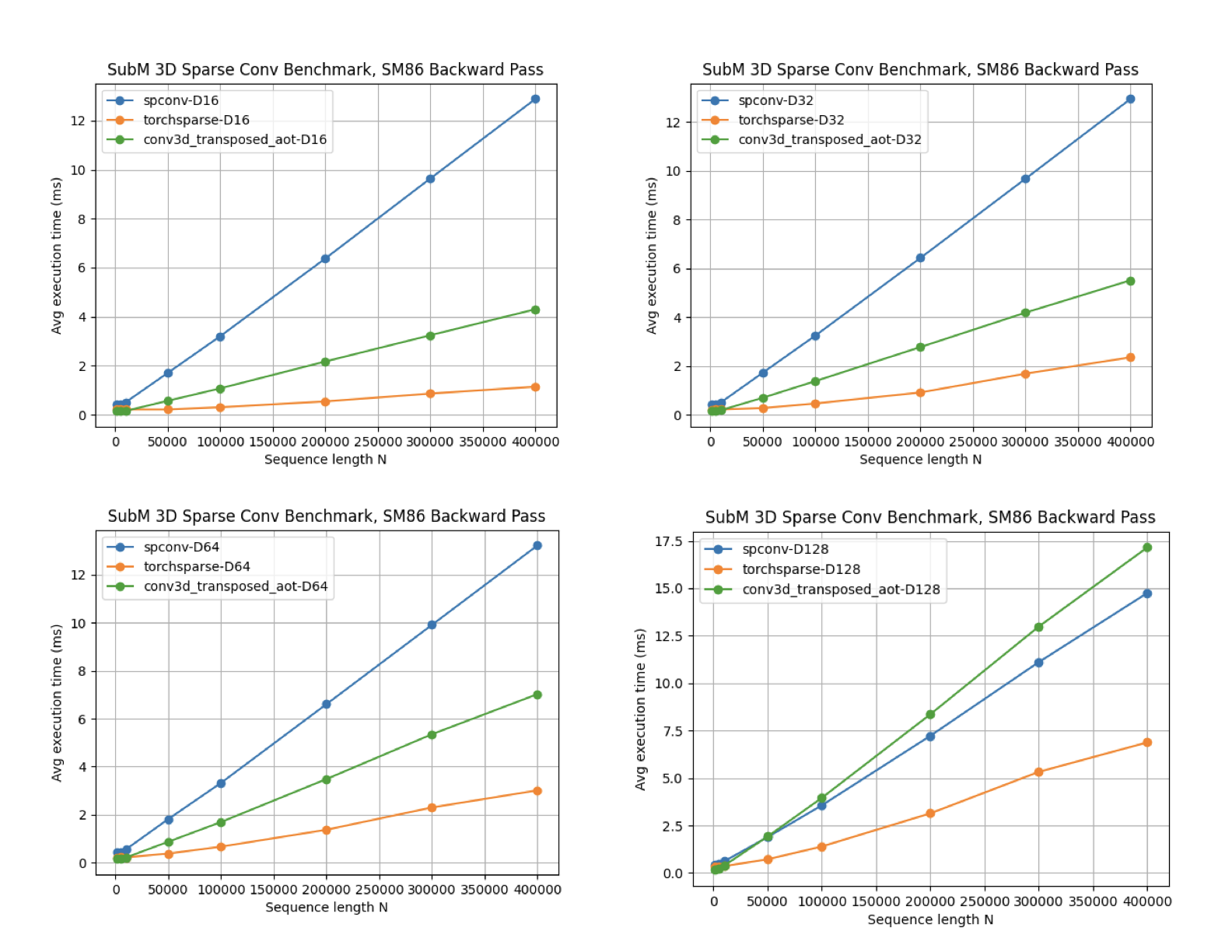
I open sourced the work here: https://github.com/Aalanli/sparse-conv.
- Reduced inference time by 50ms by using TensorRT to optimize model parts.
I used TensorRT to compile a large portion of Waabi's perception model, which was a huge pain in the ass as the python tooling was horrible; random segfaults, silent numerical errors, and very very unhelpful compiler errors.
- Drastically enhanced profiling instrumentation – made profiling tools that ML-ENG team uses daily
I used the cuda-events API and hooked onto Waabi's onboard runtime environment to generate profile traces, which was kind of non-trivial given their build system and onboard tech mish-mash.
- Solved numerical training instability of Waabi’s production ML model by developing a Dash application to trace PyTorch models
The perception model had some training instability issues where losses would diverge non-deterministically, eg. only for some runs. This was very challenging to root-cause as training runs were long, the training environment was a bit black-box and non-reproducible. I tracked down the issue to arise from unbounded activation spikes in the BEV, which is caused by sparse and irregular data on the road.
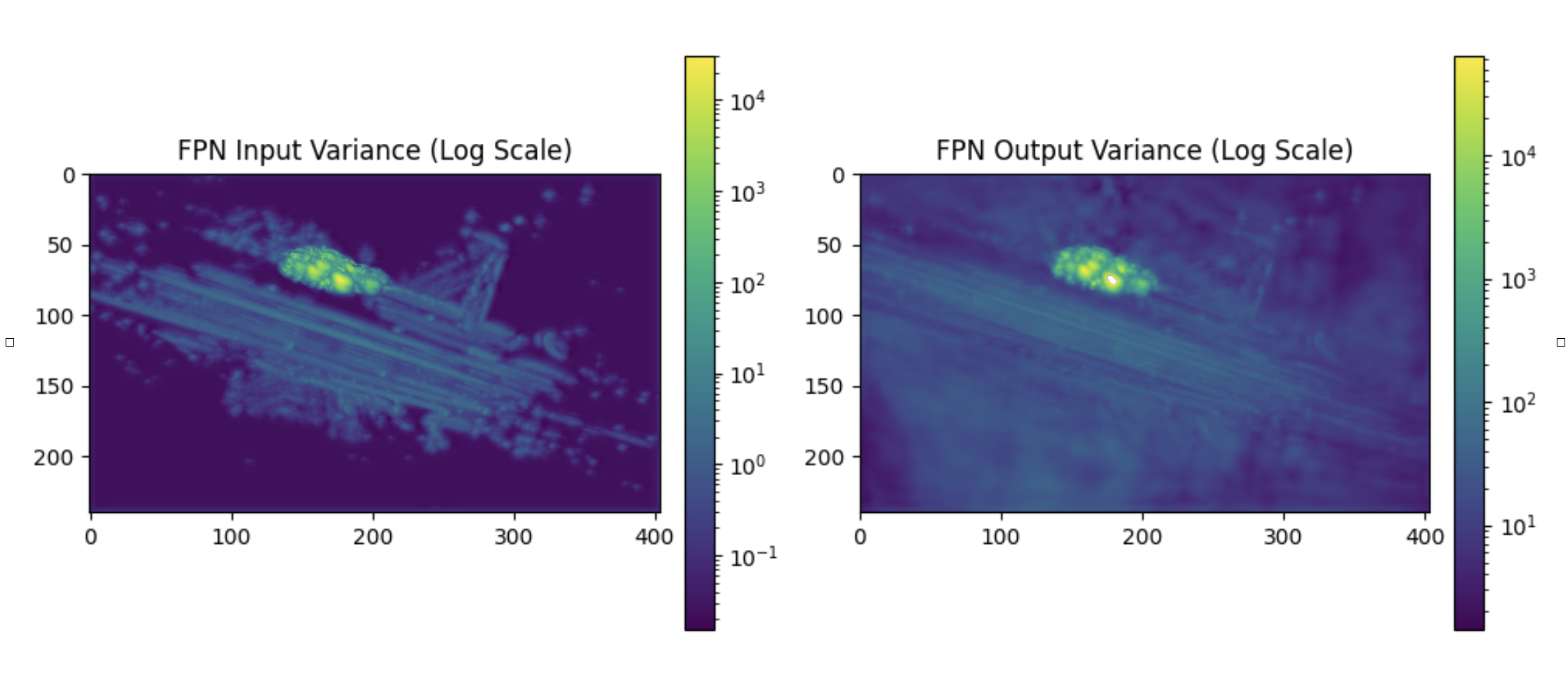
And probably an unstable training objective.
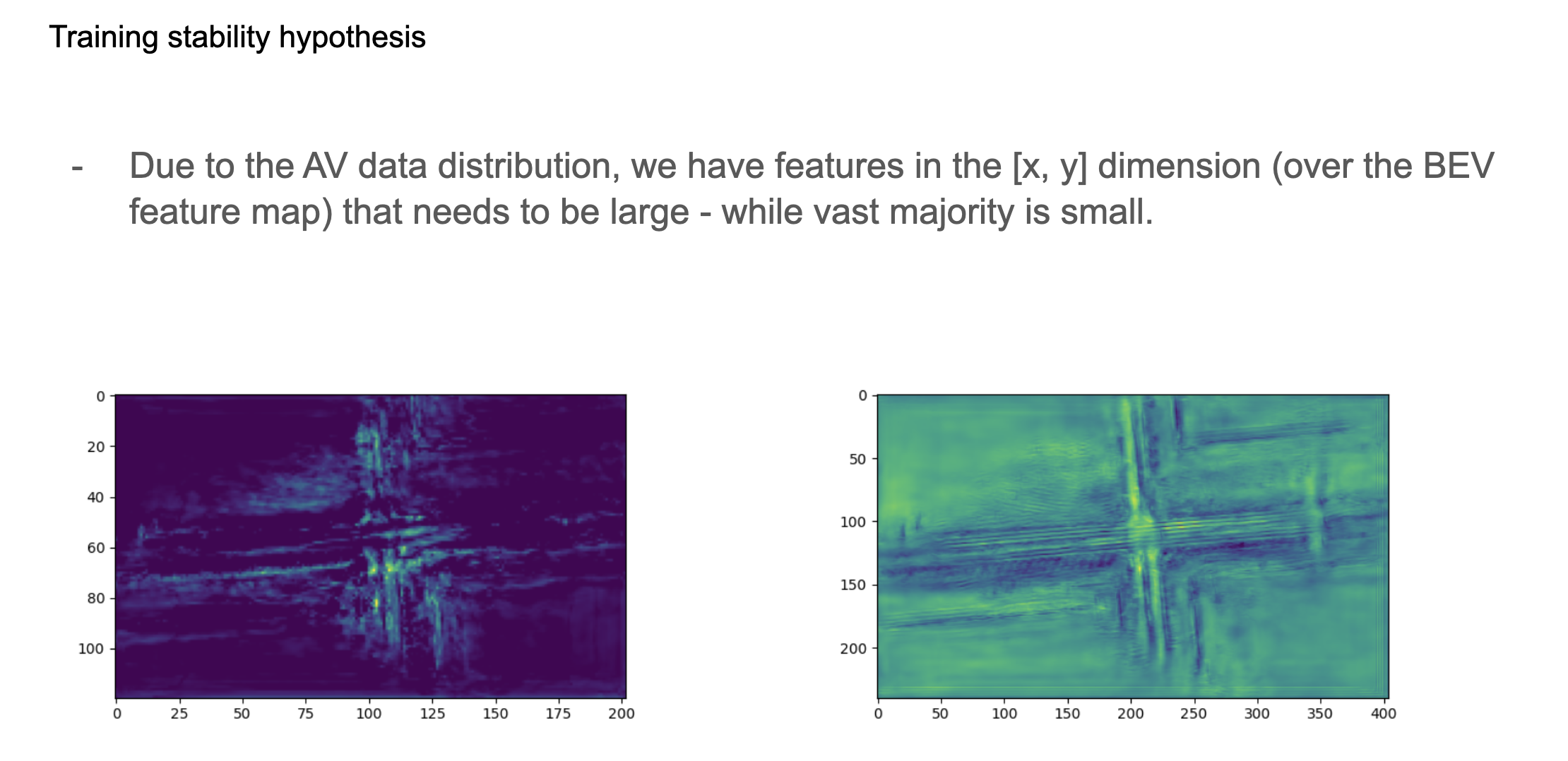
The fix involved a hard-clamp on the activations for key parts of the model which prevented these irregularities from occurring, and as a bonus we increased the learning rate and improved metrics. In the course of model debugging I developed a tool, the Dash app, that visualized PyTorch model graphs and helped a lot with finding a fix. The visualizer tool uses torch dynamo to capture the model graph, interprets it, and visualizes the connections.